Kaggle:Home Credit Default Risk 数据探索及可视化(1) |
您所在的位置:网站首页 › kaggle 培训 › Kaggle:Home Credit Default Risk 数据探索及可视化(1) |
Kaggle:Home Credit Default Risk 数据探索及可视化(1)
|
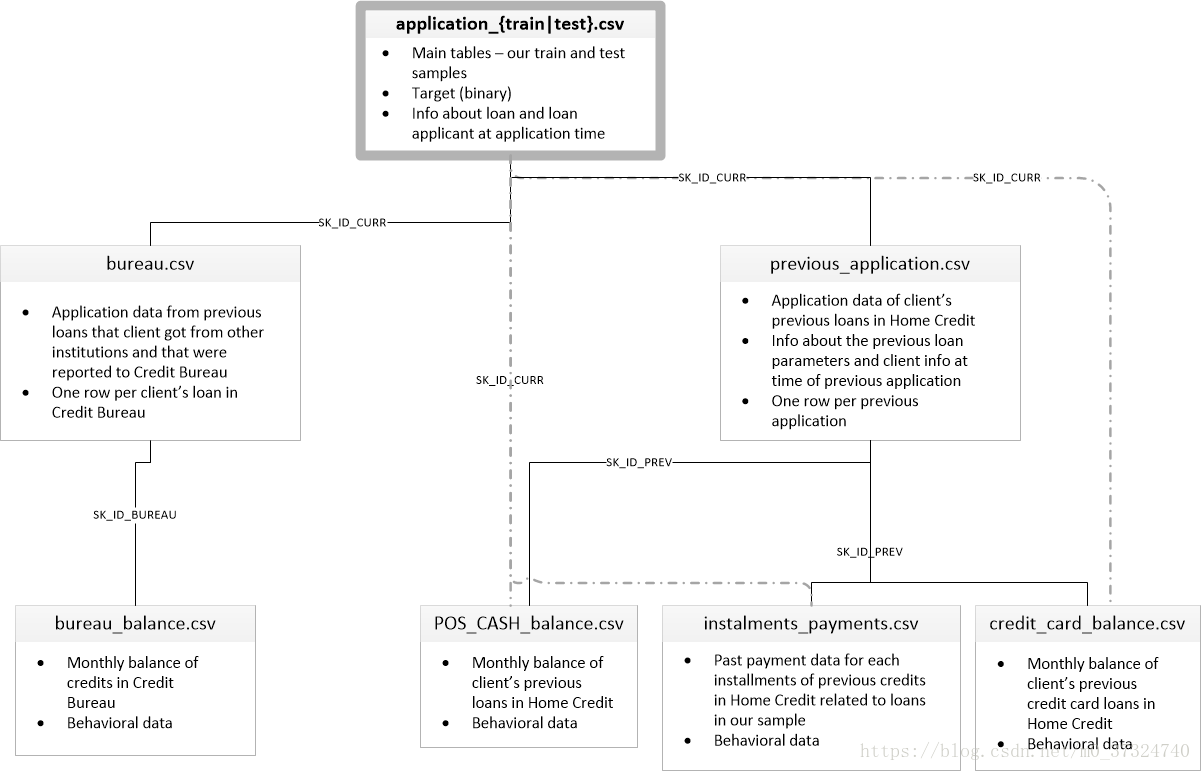
最近博主在做个 kaggle 竞赛,有个 Kernel 的数据探索分析非常值得借鉴,博主也学习了一波操作,搬运过来借鉴,原链接如下: https://www.kaggle.com/willkoehrsen/start-here-a-gentle-introduction 1 数据介绍数据由Home Credit提供,该服务致力于向无银行账户的人群提供信贷(贷款)。预测客户是否偿还贷款或遇到困难是一项重要的业务需求,Home Credit将在Kaggle上举办此类竞赛,以了解机器学习社区可以开展哪些模式以帮助他们完成此任务。 有7种不同的数据来源: application_train / application_test: 主要的培训和测试数据以及关于Home Credit每个贷款申请的信息。每笔贷款都有自己的行,并由功能SK_ID_CURR标识。培训申请数据附带TARGET表示0:贷款已还清或1:贷款未还清。 bureau: 有关客户之前来自其他金融机构的信贷的数据。以前的每一笔信贷都有自己的分行,但申请数据中的一笔贷款可能有多笔先前信贷。 bureau_balance: 关于主管局以前信用的月度数据。每一行都是上一个信用的一个月,并且一个先前的信用可以有多个行,每个信用额度的每个月有一个行。 previous_application: 之前在申请数据中拥有贷款的客户的Home Credit贷款申请。申请数据中的每个当前贷款都可以有多个以前的贷款。每个以前的应用程序都有一行,并由功能SK_ID_PREV标识。 POS_CASH_BALANCE:关于客户以前的销售点或现金贷款与住房贷款有关的每月数据。每一行都是前一个销售点或现金贷款的一个月,以前的一笔贷款可以有多行。 credit_card_balance: 有关之前的信用卡客户与Home Credit有关的每月数据。每行都是信用卡余额的一个月,一张信用卡可以有多行。 installments_payment: Home Credit以前贷款的付款记录。每笔付款都有一行,每笔未付款都有一行。 下图显示了所有数据是如何相关的: 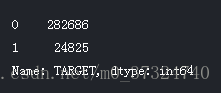 app_train['TARGET'].astype(int).plot.hist();
app_train['TARGET'].astype(int).plot.hist();
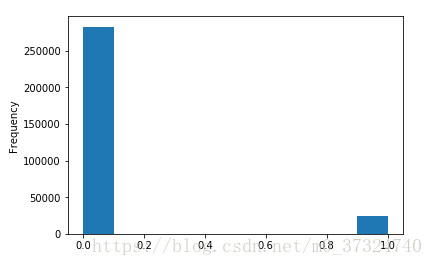 根据这些信息,我们发现这是一个不平衡的课堂问题。 按时还款的贷款远远多于未还款的贷款。 一旦我们进入更复杂的机器学习模型,我们可以通过它们在数据中的表示来对类进行加权以反映这种不平衡。
2.3 检查缺损值
# Function to calculate missing values by column# Funct
def missing_values_table(df):
# Total missing values
mis_val = df.isnull().sum()
# Percentage of missing values
mis_val_percent = 100 * df.isnull().sum() / len(df)
# Make a table with the results
mis_val_table = pd.concat([mis_val, mis_val_percent], axis=1)
# Rename the columns
mis_val_table_ren_columns = mis_val_table.rename(
columns = {0 : 'Missing Values', 1 : '% of Total Values'})
# Sort the table by percentage of missing descending
mis_val_table_ren_columns = mis_val_table_ren_columns[
mis_val_table_ren_columns.iloc[:,1] != 0].sort_values(
'% of Total Values', ascending=False).round(1)
# Print some summary information
print ("Your selected dataframe has " + str(df.shape[1]) + " columns.\n"
"There are " + str(mis_val_table_ren_columns.shape[0]) +
" columns that have missing values.")
# Return the dataframe with missing information
return mis_val_table_ren_columns
# Missing values statistics
missing_values = missing_values_table(app_train)
missing_values.head(20)
根据这些信息,我们发现这是一个不平衡的课堂问题。 按时还款的贷款远远多于未还款的贷款。 一旦我们进入更复杂的机器学习模型,我们可以通过它们在数据中的表示来对类进行加权以反映这种不平衡。
2.3 检查缺损值
# Function to calculate missing values by column# Funct
def missing_values_table(df):
# Total missing values
mis_val = df.isnull().sum()
# Percentage of missing values
mis_val_percent = 100 * df.isnull().sum() / len(df)
# Make a table with the results
mis_val_table = pd.concat([mis_val, mis_val_percent], axis=1)
# Rename the columns
mis_val_table_ren_columns = mis_val_table.rename(
columns = {0 : 'Missing Values', 1 : '% of Total Values'})
# Sort the table by percentage of missing descending
mis_val_table_ren_columns = mis_val_table_ren_columns[
mis_val_table_ren_columns.iloc[:,1] != 0].sort_values(
'% of Total Values', ascending=False).round(1)
# Print some summary information
print ("Your selected dataframe has " + str(df.shape[1]) + " columns.\n"
"There are " + str(mis_val_table_ren_columns.shape[0]) +
" columns that have missing values.")
# Return the dataframe with missing information
return mis_val_table_ren_columns
# Missing values statistics
missing_values = missing_values_table(app_train)
missing_values.head(20)
 当需要建立我们的机器学习模型时,我们将不得不填写这些缺失值(称为插补)。 在以后的工作中,我们将使用XGBoost等模型,可以处理缺失值而不需要插补。 另一种选择是删除缺失值比例较高的列,但如果这些列对我们的模型有帮助,则不可能提前知道。 因此,我们现在将保留所有列。
2.4 查看列类型
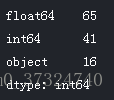
# Number of each type of column
app_train.dtypes.value_counts()
当需要建立我们的机器学习模型时,我们将不得不填写这些缺失值(称为插补)。 在以后的工作中,我们将使用XGBoost等模型,可以处理缺失值而不需要插补。 另一种选择是删除缺失值比例较高的列,但如果这些列对我们的模型有帮助,则不可能提前知道。 因此,我们现在将保留所有列。
2.4 查看列类型
# Number of each type of column
app_train.dtypes.value_counts()
 现在我们来看看每个对象(分类)列中唯一条目的数量。
app_train.select_dtypes('object').apply(pd.Series.nunique, axis = 0)
现在我们来看看每个对象(分类)列中唯一条目的数量。
app_train.select_dtypes('object').apply(pd.Series.nunique, axis = 0)
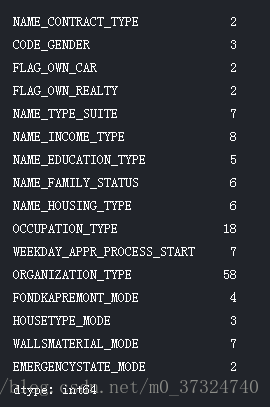 大多数分类变量的唯一条目数量相对较少。 我们需要找到一种方法来处理这些分类变量!
2.5 编码分类变量 在我们继续前进之前,我们需要处理讨厌的分类变量。 不幸的是,机器学习模型不能处理分类变量(除了LightGBM等一些模型)。 因此,我们必须找到一种将这些变量编码(表示)为数字的方式,然后再将它们交给模型。 有两种主要的方法来执行这个过程:
标签编码:使用整数分配分类变量中的每个唯一类别。 没有创建新列。 一个例子如下所示:
大多数分类变量的唯一条目数量相对较少。 我们需要找到一种方法来处理这些分类变量!
2.5 编码分类变量 在我们继续前进之前,我们需要处理讨厌的分类变量。 不幸的是,机器学习模型不能处理分类变量(除了LightGBM等一些模型)。 因此,我们必须找到一种将这些变量编码(表示)为数字的方式,然后再将它们交给模型。 有两种主要的方法来执行这个过程:
标签编码:使用整数分配分类变量中的每个唯一类别。 没有创建新列。 一个例子如下所示:
 单热编码:为分类变量中的每个唯一类别创建一个新列。 每个观察结果在其相应类别的列中收到1,在所有其他新列中收到0。
单热编码:为分类变量中的每个唯一类别创建一个新列。 每个观察结果在其相应类别的列中收到1,在所有其他新列中收到0。
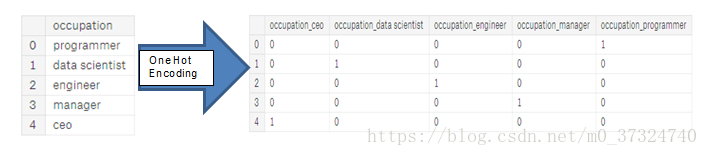 标签编码的问题在于它给了类别一个任意的顺序。 分配给每个类别的值是随机的,并不反映该类别的任何固有方面。 在上面的例子中,程序员收到一个4和数据科学家a 1,但如果我们再次执行相同的过程,标签可能会颠倒或完全不同。 整数的实际赋值是任意的。 因此,当我们执行标签编码时,模型可能会使用特征的相对值(例如程序员= 4和数据科学家= 1)来分配不是我们想要的权重。 如果我们对于分类变量(例如男性/女性)只有两个唯一值,那么标签编码很好,但对于超过2个独特类别,单热编码是安全的选择。
标签编码的问题在于它给了类别一个任意的顺序。 分配给每个类别的值是随机的,并不反映该类别的任何固有方面。 在上面的例子中,程序员收到一个4和数据科学家a 1,但如果我们再次执行相同的过程,标签可能会颠倒或完全不同。 整数的实际赋值是任意的。 因此,当我们执行标签编码时,模型可能会使用特征的相对值(例如程序员= 4和数据科学家= 1)来分配不是我们想要的权重。 如果我们对于分类变量(例如男性/女性)只有两个唯一值,那么标签编码很好,但对于超过2个独特类别,单热编码是安全的选择。
关于这些方法的相对优点存在一些争议,并且一些模型可以处理标签编码的分类变量而没有问题。 这是一个很好的Stack Overflow讨论。 我认为(这只是一种个人观点)对于有很多类的分类变量,单热编码是最安全的方法,因为它不会对类别强加任意值。 单热编码唯一的缺点是特征的数量(数据的维数)会随着分类变量的分类而爆炸。 为了解决这个问题,我们可以执行一个热门的编码,然后是 PCA 或其他降维方法,以减少维数(同时仍试图保留信息)。 我们将使用标签编码来处理任何仅有2个类别的分类变量,对于超过2个类别的任何分类变量使用单向编码。 2.6 标签编码和单热编码让我们实现上面描述的策略:对于具有2个唯一类别的任何分类变量(dtype ==对象),我们将使用标签编码,对于具有多于2个唯一类别的任何分类变量,我们将使用单热编码。 对于标签编码,我们使用Scikit-Learn LabelEncoder和一个热门编码,即熊猫get_dummies(df)函数。 # Create a label encoder object le = LabelEncoder() le_count = 0 # Iterate through the columns for col in app_train: if app_train[col].dtype == 'object': # If 2 or fewer unique categories if len(list(app_train[col].unique())) |
【本文地址】
今日新闻 |
推荐新闻 |